




قیمت: نامشخص
Toggle dropdown دریافت داده
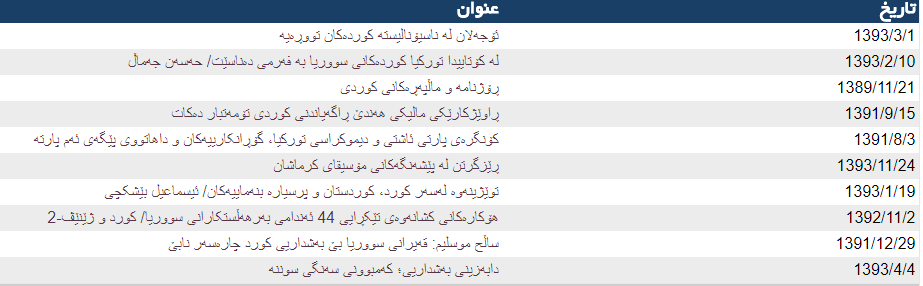
پروژۀ پیکرۀ متنی زبان کردی نخستین پیکرۀ برخط موجود به زبان کردی (گویش سورانی) است که در دانشگاه کردستان شروع به فعالیت نموده است. در جمعآوری متون این پیکره، از وبگاههای خبری کردی مانند کوردپرس استفاده شده است و پس از نرمالسازی گزارش آماری زیر به دست آمده است:
نسخۀ فعلی این پیکره شامل ۶۹۰۰۰ سند خبری است که محتوای آنها شامل اخبار گوناگون از دستههای مختلف است. مراحل برچسبزنی نحوی پیکره با ۴۰ سند شروع شد، و اسناد با دقت تمام برچسب خوردهاند. این اسناد شامل ۱۴,۸۹۸,۰۶۲ کلمه میباشند که از این تعداد واژه، ۴۳۶,۶۵۵ واژه منحصربهفرد هستند. لازم به ذکر است که بر روی پیکره، از ریشهیاب استفاده نشده است و این عدد به واژههای خام بدون ریشهیابی اشاره دارد. به عنوان مثال دو واژۀ «کتێب» و «کتێبەکان» دو واژۀ منحصربهفرد محاسبه شدهاند.پراکندگی سایزی فایلهای متنی از ۲ کیلو بایت تا ۲۴۷ کیلو بایت میباشد و پراکندگی زمانی از سال ۱۳۸۹ تا ۱۳۹۴ است. این پیکره توسط تیم پژوهشی پیکرۀ زبان کردی آغاز گردیده، و با حمایت دانشگاه کردستان و استانداری کردستان ادامه یافته است.
بدخشان، ا.، کریمی، ی.، و صلواتی، ش. (۱۳۹۵). ایجاد پیکرۀ زبان کردی. کردستان: دانشگاه کردستان.
اطلاعات انتشار:
| ناشر | |
|---|---|
| شرایط استفاده | برای دریافت داده یا کسب اطلاعات بیشتر با ناشر(ان) تماس حاصل فرمایید. |
| مجوز | نامشخص |
| تاریخ ثبت در پیکرهگان | ۱۳۹۷-۰۲-۲۹ |
| تاریخ آخرین تغییر | ۱۳۹۸-۰۲-۲۹ |
| شناسه | P3970229c |
| آمار بازدید | ۴۲۶۸ |

{kind=link}