




قیمت: رایگان
معرفی:
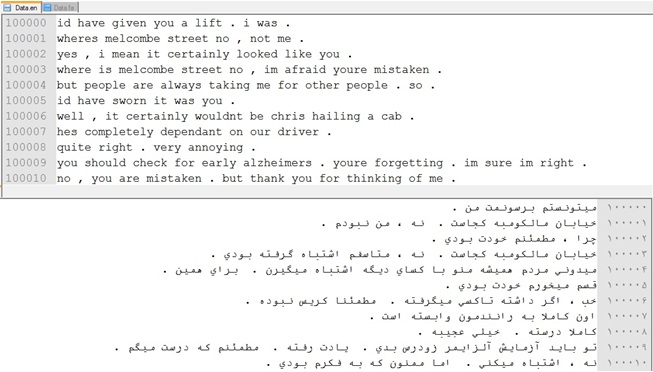
پیکرهٔ موازی انگلیسی-فارسی تهران (TEP) مجموعهای است حاوی بیش از ششصدهزار جملهٔ همترازشده انگلیسی و فارسی که از زیرنویس ۱۶۰۰ فیلم استخراج شدهاند. این پیکره در آزمایشگاه پردازش زبان طبیعی دانشگاه تهران تهیه شده است و در ماشینهای ترجمه و دیگر سیستمهای پردازش زبان طبیعی کاربرد دارد.
*اطلاعات ارجاع:
Pilevar, M. T., Faili, H., Pilevar, A. H. (2011). TEP: Tehran English-Persian Parallel Corpus. In Proceedings of the 12th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing'11), ۶۸-۷۹, Tokyo, Japan.(دریافت)
اطلاعات تکمیلی:
اطلاعات انتشار:
| ناشر | |
|---|---|
| مجوز | اختصاصی |
| تاریخ ثبت در پیکرهگان | ۱۳۹۲-۰۲-۱۴ |
| تاریخ آخرین تغییر | ۱۳۹۸-۰۲-۰۳ |
| شناسه | D3920214a |
| آمار بازدید | ۱۱۰۲۴ |

{kind=link}