




قیمت: رایگان
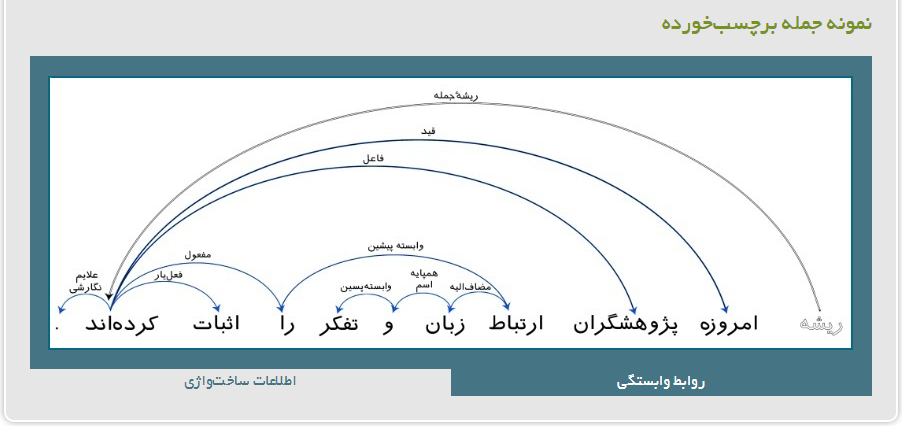
پیکره وابستگی نحوی زبان فارسی نخستین پیکره نحوی زبان فارسی است شامل حدود ۳۰ هزار جملۀ برچسبخورده که اطلاعات نحوی و ساختواژی را بر مبنای دستور وابستگی تهیه و عرضه نموده است. مهمترین دلائل استفاده از دستور وابستگی در این پیکره نحوی عبارتند از: نتایج رضایتبخش در یادگیری خودکار و سازگاری مناسب با طبیعت زبانهای بیترتیب همچون زبان فارسی («من در مدرسه کتاب را به علی دادم»، «من در مدرسه به علی کتاب را دادم»، «من به علی در مدرسه کتاب را دادم»، «من کتاب را به علی در مدرسه دادم»).
- جملات پیکره برگرفته از منابع مختلفی از متون فارسی معاصر هستند.
- تمامی جملات دارای برچسب روابط نحوی (بر مبنای دستور وابستگی) از قبیل فاعل، مفعول، مسند، مضافالیه، بدل ... هستند.
- تمامی جملات دارای برچسب اطلاعات ساختواژی (برچسب اجزای سخن - POS) از قبیل فعل، اسم، صفت، قید، ضمیر ... هستند.
- جملات توسط تیمی از زبانشناسان مجرب برچسب خوردهاند و در چند مرحله بازبینی شدهاند.
- دادههای پیکره بر اساس قالب همایش زبانشناسی رایانهای و پردازش زبان طبیعی بر روی پیکرههای وابستگی فراهم آمده است.
- دادههای پیکره به صورت تصادفی به دادههای یادگیری (۸۰%)، آزمون (۱۰%) و ارزیابی (۱۰%) تقسیم شده است.
برخی آمار مربوط به پیکره:
- تعداد کل جملات: ۲۹٫۹۸۲
- تعداد کل واژهها: ۴۹۸٫۰۸۱
- تعداد واژههای منحصر به فرد: ۳۷٫۶۱۸
- میانگین طول هر جمله: ۶۱/۱۶
- تعداد افعال منحصر به فرد: ۴٫۷۸۲
- میانگین حضور هر فعل: ۶۷/۱۲
Rasooli, M. S. Kouhestani, M. and Moloodi, A. S. (2013). Development of a Persian Syntactic Dependency Treebank. In The 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT), Atlanta, USA. (دریافت)
- - رسولی، م. ص. کوهستانی، م. و مولودی، ا. س. (۱۳۹۳) . پیکره نحوی زبان فارسی: پژوهشی بر اساس دستور وابستگی. تهران: دبیرخانهٔ شورای عالی اطلاعرسانی. ISBN/شابک:۹۷۸۹۶۴۸۸۴۶۳۷۹
- گزارش نهایی و راهنمای پیکره وابستگی نحوی زبان فارسی - فارسی / انگلیسی
- دادگان زبان فارسی بر اساس دستور وابستگی - ارائهشده در گروه پردازش زبان طبیعی مرکز سامانههای یادگیری رایانهای دانشگاه کلمبیا نیویورک (نوامبر ۲۰۱۲)
- شرح کار پروژه دادگان وابستگی زبان فارسی - ارائهشده در سمینار معرفی پروژه در دانشگاه صنعتی شریف (۱۳ اردیبهشت ۱۳۹۱)
- کارکرد پروژه دادگان و پردازش متون زبانی - مصاحبۀ روزنامه تهران امروز با مدیر پروژه (۱۶ بهمن ۱۳۹۰)
- پیکره متنی بر اساس دستور وابستگی، راهکارها و چالشها
- تجزیه وابستگی - ارائهشده در کلاس پردازش زبانهای طبیعی دانشکده مهندسی برق و کامپیوتر دانشگاه تهران (۱۷ اردیبهشت ۱۳۹۱)
- تجزیه وابستگی - خلاصهای از کتاب تجزیه وابستگی (۲۰۰۹) و مقالات موجود در مورد تجزیه وابستگی
سرپرستی پروژه و پژوهش زبانشناسی رایانهای
- محمدصادق رسولی، کارشناس ارشد هوش مصنوعی، دانشگاه علم و صنعت ایران
پژوهش و آموزش زبانشناسی
- منوچهر کوهستانی، دانشجوی دکتری زبانشناسی، دانشگاه تربیت مدرس
- امیرسعید مولودی، دانشجوی دکتری زبانشناسی، دانشگاه تهران
برچسبزنی زبانشناختی
- سحر اولیپور، کارشناس ارشد زبانشناسی، دانشگاه تهران
- فرزانه بختیاری، دانشجوی کارشناسی ارشد زبانشناسی، دانشگاه تهران
- ندا پورمرتضی خامنه، کارشناس ارشد زبان و ادبیات فارسی، دانشگاه آزاد اسلامی
- پریناز دادرس، دانشجوی کارشناسی ارشد زبانشناسی، دانشگاه تهران
- سوده رسالتپو، کارشناس ارشد زبانشناسی، دانشگاه آزاد اسلامی علوم و تحقیقات
- مرتضی رضائی شریفآبادی، دانشجوی کارشناسی ارشد زبانشناسی رایانشی، دانشگاه صنعتی شریف
- سلیمه زمانی، کارشناس ارشد زبانشناسی، دانشگاه آزاد اسلامی علوم و تحقیقات
- اکرم شفیعی، کارشناس ارشد زبانشناسی، دانشگاه تهران
- مریم فعال همدانچی، دکترای زبانشناسی، دانشگاه دوستی ملل روسیه
- سعیده قدردوست نخچی، کارشناس ارشد زبانشناسی، دانشگاه تهران
- مصطفی مهدوی، دانشجوی دکتری زبانشناسی، پژوهشگاه علوم انسانی و مطالعات فرهنگی
- آزاده میرزائی، دانشجوی دکتری زبانشناسی، دانشگاه علامه طباطبایی
برنامهنویسی
- سید مهدی حسینی، کارشناس ارشد هوش مصنوعی، دانشگاه علم و صنعت ایران
- یاسر سوری، دانشجوی کارشناسی ارشد هوش مصنوعی، دانشگاه صنعتی شریف
- علیرضا نوریان، دانشجوی کارشناسی ارشد هوش مصنوعی، دانشگاه علم و صنعت ایران
اطلاعات انتشار:
| ناشر | |
|---|---|
| مالکیت معنوی | مرکز تحقیقات کامپیوتری علوم اسلامی (نور) |
| مجوز | |
| تاریخ ثبت در پیکرهگان | ۱۳۹۱-۱۱-۰۳ |
| تاریخ آخرین تغییر | ۱۳۹۹-۰۶-۰۲ |
| شناسه | D3911103a |
| آمار بازدید | ۱۹۵۳۳ |

{kind=link}